Device Resiliency
Device and Connection Resiliency Defined
Network Edge offers multiple resiliency options that can be summarized as device options and connection options. Device options are local and provide resiliency against failure at the compute and device level in the local metro. This is analogous to what the industry typically refers to as “High Availability (HA)”. Connection resiliency is a separate option for customers that require additional resiliency with device connections (DLGs, VCs and EVP-LAN networks).
It is common to combine both local resiliency and connection resiliency, but it is not required - Ultimately it depends on the customer’s business requirement.
Geo-redundancy is an architecture that expands on local resiliency by utilizing multiple metros to eliminate issues that may affect Network Edge at the metro level. Geo-redundancy is discussed in detail here.
Single (Standalone) Devices – Local Resiliency Option
Single or standalone devices have no resiliency for compute and device failures. The first single device is always connected to the Primary Compute Plane. Single devices always make connections over the Primary Fabric network. Single devices can build redundant connections (VCs, DLGs, etc.) but they will always traverse the Primary Fabric plane. Single devices can be converted to Redundant Devices via the anti-affinity feature.
Single Device Anti-Affinity
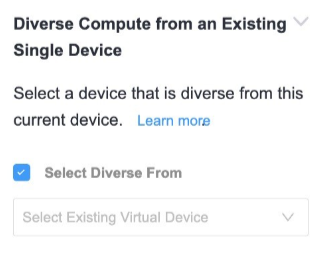
As described earlier, single devices have no resiliency by default. However, single devices can be placed in divergent compute planes. This is commonly called anti-affinity and is available in the device creation workflow. Under the Diverse Compute from an Existing Single Device section, checking the “Select Diverse From” box allows customers to add new devices that are resilient to each other.
Redundant Virtual Devices
Network Edge workflows ensure paired virtual devices in a fault-tolerant deployment are placed on Primary and Secondary compute planes. There are two types of fault-tolerant deployments: Redundant devices and Clustered devices.
These options provide local, intra-metro resiliency to protect against hardware or power failures in the local Network Edge POD. By default, the two virtual devices are deployed in separate compute planes (Primary and Secondary) and they are distinct from each other. The primary device is connected to the Primary Fabric network and the secondary/passive device is connected to the Secondary Fabric network. The deployment type selection is available from the device creation workflow in the portal.
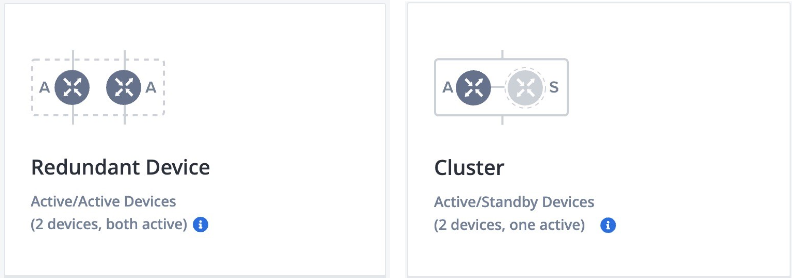
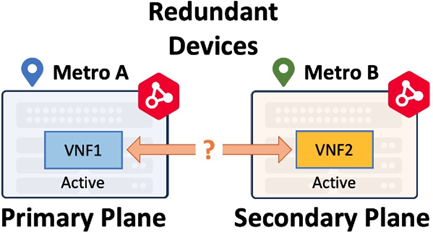
Redundant virtual instances are deployed on different compute planes for redundancy. They have no higher-level workflows, meaning the devices are unaware of each other after initial deployment and function as two distinct virtual devices. Typically, redundant devices function in an Active-Active fashion. Redundant virtual instances can be deployed in a same metro or across metros. Redundant device in a single metro only provides local resiliency. Geo-redundancy deployment (redundant devices across metros) provides much higher resiliency. When a redundant device is deployed in another metro, it is still deployed in the secondary compute plane.
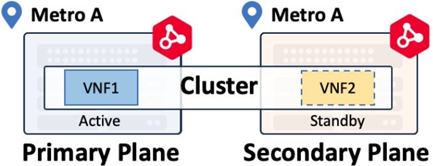
Cluster Virtual Devices
Cluster virtual instances have higher-level workflows that will deploy an Active-Standby device pair as defined by the respective vendor. Check the documentation to verify Cluster support for your virtual device. Cluster devices can only be deployed within the same metro.