Arquitectura para la resiliencia
Este tema proporciona una visión general de las soluciones tolerantes a fallos que puede conseguir utilizando Network Edge.
Diseñar soluciones con capacidad de recuperación es uno de los aspectos más críticos de la arquitectura de red y de borde. Aunque no existe una respuesta correcta sobre cuánta resiliencia se necesita, sí hay mejores prácticas, sugerencias para diferentes casos de uso y algunos servicios y características específicos que ofrece Network Edge.
La plataforma subyacente de virtualización de funciones de red (NFV) que proporciona la infraestructura para Network Edge es inherentemente tolerante a fallos desde el punto de vista de una única instancia virtual. Aún así, debe diseñar la resiliencia en la solución global para lograr la máxima redundancia posible. Este documento explica cómo lograr resiliencia utilizando la naturaleza inherente de la plataforma complementada por las características tolerantes a fallos de Network Edge.
Niveles de redundancia
Imagina un diseño de red desde el origen de un paquete de datos y moviéndose desde dentro hacia fuera hasta su destino. En ese caso, cada punto donde se procesa o atraviesa el tráfico se convierte en un posible punto de fallo. La clave es diseñar contra un evento que impacte en los puntos de cruce.
En un flujo de red sencillo desde un dispositivo Network Edge a un participante de Equinix Fabric, como se muestra en el siguiente gráfico, los flujos de tráfico tienen tres puntos distintos: El dispositivo virtual Network Edge, Equinix Fabric y la conexión del participante Fabric. Existe una redundancia inherente entre el dispositivo virtual Network Edge y Equinix Fabric, por lo que la arquitectura Leaf o Spine que interconecta la plataforma NFV subyacente con el Fabric es redundante. No hay redundancia inherente entre Equinix Fabric y el participante Fabric. Para lograr la máxima redundancia, debe desplegar una solución que utilice diferentes planos de conectividad para aprovechar el flujo de red completo.

Planos primarios y secundarios
El Network Edge se basa en una arquitectura de redundancia de centros de datos estándar con múltiples puntos de despliegue (POD) que cuentan con un suministro de energía dedicado. El concepto de planos Primario y Secundario está detrás del despliegue de Network Edge y Equinix Fabric. Network Edge utiliza los planos Primario y Secundario mediante la separación informática por afinidad. Cada dispositivo virtual de un par tolerante a fallos se despliega en su respectivo clúster. Aunque se denominan Plano Primario y Plano Secundario, existen múltiples planos de cálculo en cada uno de los POD de Network Edge. El número real varía en función del tamaño del metro. Esto permite desplegar los dispositivos de forma que no estén mezclados en el mismo plano de cálculo, eliminando el cálculo como punto único de fallo (SPOF).
Los conmutadores Equinix Fabric forman parte de un grupo de chasis que consta de conmutadores Primarios y Secundarios. Las designaciones de conmutador Primario y Secundario para el grupo de chasis son simplemente una forma de identificar los conmutadores desde el punto de vista de la nomenclatura y no muestran los flujos de tráfico. Activo-Activo o Activo-En espera desde el punto de vista del enrutamiento se configuran en el dispositivo Network Edge y están completamente bajo su control. La documentación sobre la arquitectura de la plataforma trata más detalles sobre la arquitectura fundacional de Network Edge.
Previamente se ha desplegado una VNF de cortafuegos denominada NGFW-A. Para desplegar una VNF de enrutador en el plano secundario, utilice la función Diverse Compute from an Existing Single Device y seleccione NGFW-A en el menú desplegable.
Definición de la resistencia de dispositivos y conexiones
Network Edge ofrece múltiples opciones de resistencia que pueden resumirse en opciones de dispositivo y opciones de conexión. Las opciones de dispositivo son locales y proporcionan resiliencia frente a fallos a nivel informático y de dispositivo en el metro local. Esto es análogo a lo que el sector suele denominar "alta disponibilidad (HA)". La resistencia de conexión es una opción separada para clientes que requieren resistencia adicional con conexiones de dispositivos (DLGs, VCs y redes EVP-LAN).
Es habitual combinar tanto la resistencia local como la resistencia de conexión, pero no es obligatorio; en última instancia, depende de los requisitos empresariales del cliente.
La georredundancia es una arquitectura que amplía la capacidad de recuperación local utilizando varios metros para eliminar los problemas que puedan afectar a Network Edge a nivel metropolitano. La georredundancia se trata en detalle aquí.
Dispositivos individuales (autónomos) - Opción de resistencia local
Los dispositivos individuales o autónomos no tienen capacidad de recuperación ante fallos de computación y dispositivos. El primer dispositivo individual siempre está conectado al plano de cálculo primario. Los dispositivos individuales siempre realizan conexiones a través de la red Primary Fabric. Los dispositivos individuales pueden crear conexiones redundantes (VCs, DLGs, etc.) pero siempre atravesarán el plano Primary Fabric. Los dispositivos únicos pueden convertirse en dispositivos redundantes mediante la función antiafinidad.
Dispositivo único antiafinidad
Como se ha descrito anteriormente, los dispositivos individuales no tienen resiliencia por defecto. Sin embargo, los dispositivos individuales pueden colocarse en planos de cálculo divergentes. Esto se denomina comúnmente antiafinidad y está disponible en el flujo de trabajo de creación de dispositivos. En la sección "Diverse Compute from an Existing Single Device", si se marca la casilla "Select Diverse From", los clientes pueden añadir nuevos dispositivos que sean resistentes entre sí.
!](images/create-devices/NE-select-diverse-from.png)
Dispositivo virtual redundante frente a clúster
Los flujos de trabajo de Network Edge garantizan que los dispositivos virtuales emparejados en una implantación tolerante a fallos se coloquen en los planos de cálculo primario y secundario. Existen dos tipos de despliegues tolerantes a fallos: Dispositivos redundantes y Dispositivos agrupados.
Estas opciones proporcionan resiliencia local (intrametropolitana) para proteger frente a fallos de hardware o de alimentación en el POD local de Network Edge. Por defecto, los dos dispositivos virtuales se despliegan en planos de computación separados (Primario y Secundario) y son distintos entre sí. El dispositivo primario está conectado a la red Primary Fabric y el dispositivo secundario/pasivo está conectado a la red Secondary Fabric. La selección del tipo de despliegue está disponible en el flujo de trabajo de creación de dispositivos en el portal.
!](images/create-devices/NE-RD-CD.png)
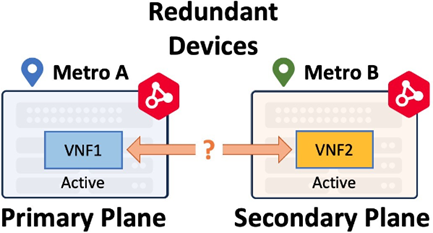
Las instancias virtuales redundantes se despliegan en diferentes planos de cálculo para conseguir redundancia. No tienen flujos de trabajo de nivel superior, lo que significa que los dispositivos no son conscientes el uno del otro después del despliegue inicial y funcionan como dos dispositivos virtuales distintos. Normalmente, los dispositivos redundantes funcionan de forma Activo-Activo. Las instancias virtuales redundantes pueden desplegarse en un mismo metro o a través de metros. Un dispositivo redundante en un único metro sólo proporciona capacidad de recuperación local. El despliegue de la georredundancia (dispositivos redundantes en varios metros) proporciona una capacidad de recuperación mucho mayor. Cuando un dispositivo redundante se despliega en otro metro, sigue desplegado en el plano de cálculo secundario.
Las instancias virtuales de Cluster tienen flujos de trabajo de nivel superior que desplegarán un par de dispositivos Activo-En espera según lo definido por el proveedor respectivo. Consulte la documentación para verificar la compatibilidad con Cluster para su dispositivo virtual. Los dispositivos Cluster sólo pueden desplegarse dentro del mismo metro.
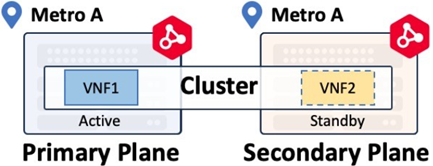
Conexiones virtuales
Las conexiones virtuales le permiten especificar el nivel de resistencia que requiere su despliegue. Los flujos de trabajo son flexibles, lo que permite múltiples escenarios para dar cabida a la redundancia, si es necesario.
Los flujos de trabajo de las conexiones virtuales difieren entre los despliegues redundantes y de clúster. Las conexiones de dispositivos redundantes se originan en cada dispositivo virtual individual del par redundante, mientras que las conexiones de dispositivos agrupados se originan en el clúster.
Conexiones virtuales redundantes
Los dispositivos redundantes se despliegan en distintos planos de cálculo mediante afinidad. Una vez desplegados, los dispositivos no comparten ninguna información de configuración y funcionan como dos dispositivos independientes. Para lograr la redundancia a través del participante Fabric, se crean conexiones virtuales en los planos Primary y Secondary Fabric como se muestra a continuación. El plano Primario se conecta a la red del Tejido Primario (o Plano del Tejido Primario) y el Plano Secundario se conecta a la red del Tejido Secundario.
Este es uno de los conceptos más importantes para comprender la capacidad de recuperación de Network Edge. El plano del dispositivo determina qué red Fabric (o Plano Fabric) se utiliza para las conexiones de los dispositivos.
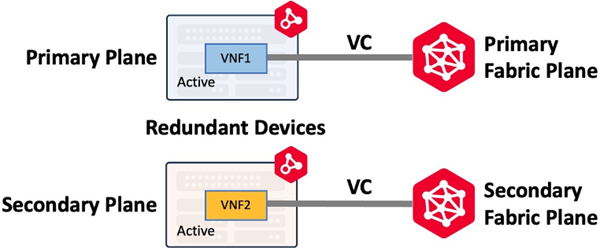
Los dispositivos redundantes pueden desplegarse en el mismo metro o en metros diferentes, lo que permite crear soluciones redundantes que abarcan distancias geográficas. Los flujos de trabajo son flexibles y se pueden crear conexiones tanto en el plano principal como en el secundario de Fabric, o en cada plano según lo requiera el caso de uso.
Conexiones virtuales del clúster
Los dispositivos agrupados se despliegan en los planos de computación primario y secundario y tienen flujos de trabajo de nivel superior para construir un par de dispositivos virtuales Activo-Activo o Activo-Estable.
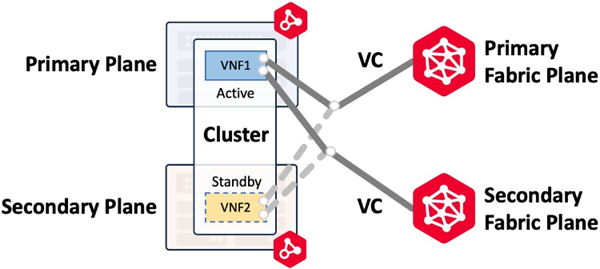
Los clústeres pueden construirse sólo en el mismo metro. Por ejemplo, si se construye un circuito virtual tanto en el plano primario como en el secundario de Fabric, el flujo de trabajo creará dos conexiones al clúster y asignará una interfaz para cada conexión a ambos nodos del clúster. La imagen siguiente (Connecting to Same Metro/Same Provider) muestra una conexión Fabric primaria y secundaria a un cluster Active-Standby con cluster-node0 activo y cluster-node1 en espera. En caso de que se produzca un fallo en el clúster y el nodo-clúster1 pase a estar activo, las conexiones se trasladarán al nodo-clúster1.
| Redundant Devices | Clustered Devices | |
|---|---|---|
| Deployment | Two devices, both Active, appearing as two devices in the Network Edge portal. Both devices have all interfaces forwarding | Two devices, only one is ever Active. The Passive (non-Active) device data plane is not forwarding |
| WAN Management | Both devices get a unique L3 address that is active for WAN management | Each node gets a unique L3 address for WAN management as well as a Cluster address that connects to the active node (either 0 or 1) |
| Device Linking Groups | None are created at device inception | Two are created by default to share configuration synchronization and failover communication |
| Fabric Virtual Connections | Connections can be built to one or both devices | Single connections are built to a special VNI that connects to the Active Cluster node only. Customer can create optional, additional secondary connection(s) |
| Supports Geo Redundancy | Yes, Redundant devices can be deployed in different metros | No, Cluster devices can only be deployed in the same metro |
| Vendor Support | All vendors | Fortinet FortiGate FirewallsJuniper vSRX FirewallsNGINX PlusPalo Alto VM-Series Firewalls |
Todos los escenarios mostrados en las siguientes ilustraciones asumen que el participante Proveedor se conecta tanto al Fabric Primario como al Secundario. Si tiene alguna duda sobre las conexiones a Fabric redundantes, consulte a su arquitecto de soluciones globales de Equinix.
Conexión al mismo metro/mismo proveedor
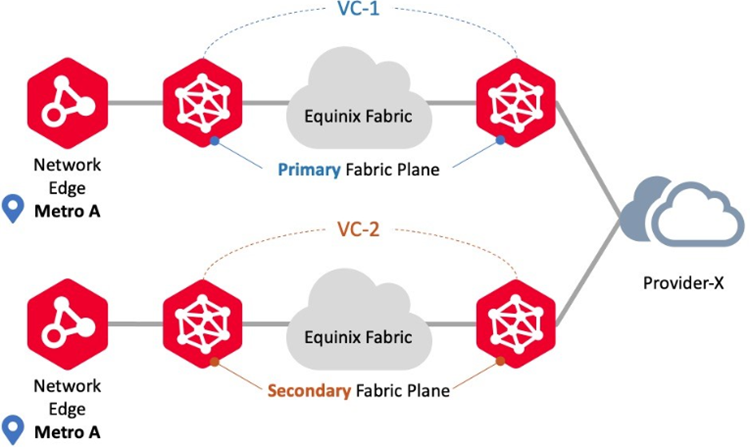
Utilice este escenario de conexión para conectarse al mismo proveedor utilizando dispositivos Network Edge en la misma ubicación metropolitana. En este escenario, Network Edge admite tanto despliegues redundantes como en clúster. Los flujos de trabajo de circuitos virtuales garantizan que cada circuito se aprovisione en los planos de Fabric primario y secundario, respectivamente. Un ejemplo son las conexiones redundantes a los mismos participantes de Fabric.
Conectarse al mismo metro o a distintos proveedores
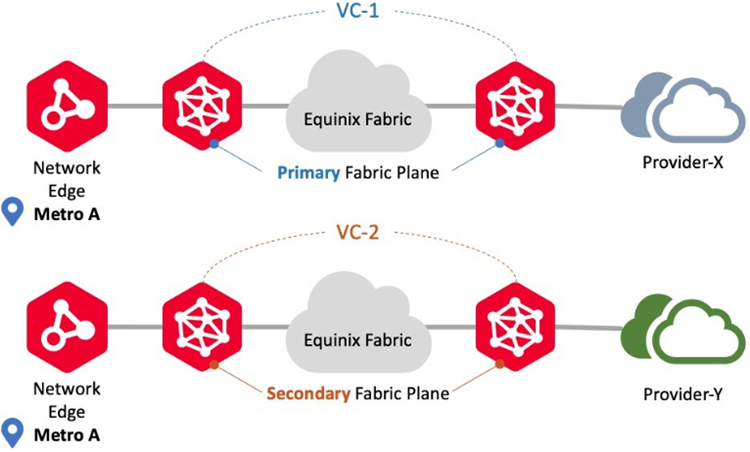
Utilice este escenario de conexión para conectarse a diferentes proveedores utilizando dispositivos Network Edge en la misma ubicación metropolitana. En este escenario, Network Edge admite tanto despliegues redundantes como en clúster. Los flujos de trabajo de circuitos virtuales garantizan que cada circuito se aprovisione en los planos de Fabric primario y secundario, respectivamente. Un ejemplo son las conexiones redundantes a diferentes participantes de Fabric.
Conectarse a otro metro o al mismo proveedor
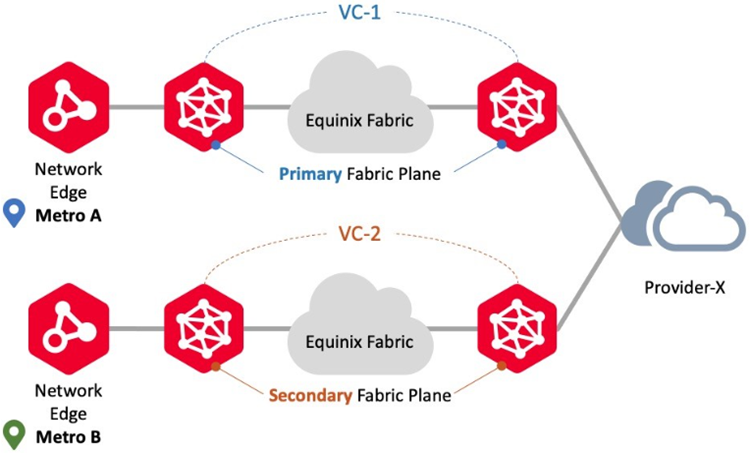
Utilice este escenario de conexión para conectarse a los mismos proveedores utilizando instancias virtuales de Network Edge en diferentes ubicaciones metropolitanas. En este escenario, Network Edge admite despliegues redundantes pero no admite despliegues en clúster. Los flujos de trabajo del circuito virtual garantizan que cada circuito se aprovisione en los planos Primary y Secondary Fabric, respectivamente. Un ejemplo son las conexiones redundantes desde dos metros diferentes al mismo participante Fabric.
Conectarse a diferentes metros/diferentes proveedores
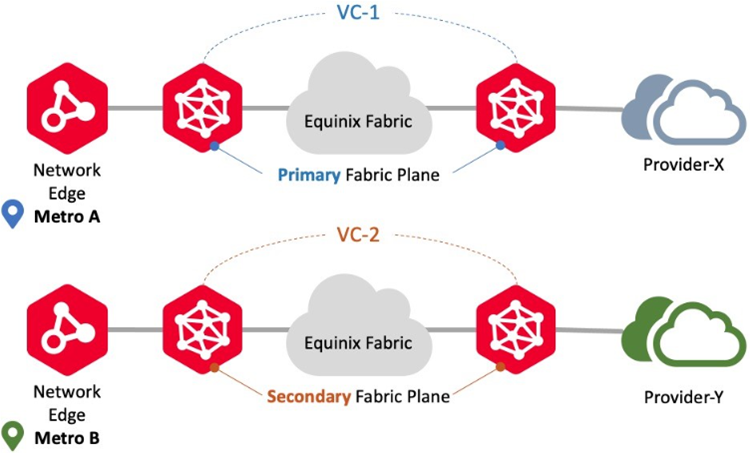
Utilice este escenario de conexión para conectarse a diferentes proveedores utilizando dispositivos Network Edge en diferentes ubicaciones metropolitanas a diferentes participantes de Fabric. En este escenario, Network Edge admite despliegues redundantes pero no admite despliegues en clúster. Los flujos de trabajo de circuitos virtuales garantizan el aprovisionamiento para cada circuito en los planos de Fabric Primario y Secundario, respectivamente. Un ejemplo son las conexiones redundantes desde dos metros diferentes a los distintos participantes de Fabric.
Grupos de enlace de dispositivos
Un grupo de enlace de dispositivos (DLG) es un servicio de Network Edge con el que se pueden conectar en grupo dos o más dispositivos virtuales dentro o a través de varios metros. Un DLG se utiliza normalmente para el encadenamiento de servicios (conexión de varios tipos de dispositivos, como cortafuegos y enrutadores, entre sí), la red troncal o con fines de redundancia.
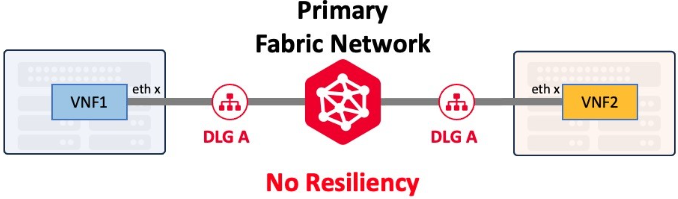
Los DLG pueden crearse con o sin redundancia. Un único DLG, al igual que un único cable Ethernet, no proporciona resistencia. Los clientes que necesiten la máxima capacidad de recuperación deben desplegar DLG adicionales que se conecten tanto a la red primaria como a la secundaria de Fabric.
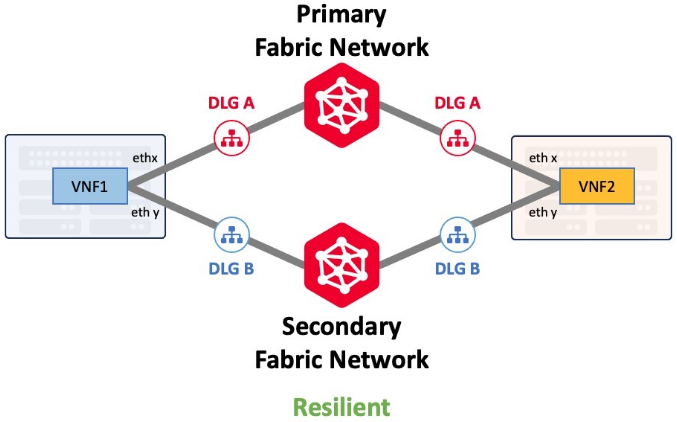
Device Link y su capacidad de redundancia se tratan en detalle en Device Link Resiliency.
EVP-Redes LAN
Network Edge admite la conexión EVP-LAN para permitir la conexión en red multipunto a multipunto. EVP-LAN le permite interconectar los activos de su centro de datos en muchas ubicaciones a través de una red común en lugar de requerir conexiones directas entre ubicaciones individuales. Este tema describe cómo crear una red privada multipunto a multipunto y conectarse a ella desde sus dispositivos Network Edge.
Las EVP-LAN se diferencian de las DLG en que se conectan a dispositivos Network Edge y a puertos Fabric. Varios dispositivos Network Edge en el mismo metro pueden formar parte de la misma red EVP-LAN. Los clientes que necesiten la máxima capacidad de recuperación deben desplegar redes EVP-LAN adicionales que abarquen tanto la red principal como la secundaria de Fabric.
Para una resistencia adecuada, cada dispositivo del par de dispositivos redundantes necesitará una única conexión a dos redes EVP-LAN diferentes. El dispositivo primario en el plano primario utilizará la red Primary Fabric. El dispositivo secundario del plano secundario utilizará la red Fabric secundaria.
Los dispositivos agrupados en clúster son diferentes en que el flujo de trabajo permite que las conexiones se construyan a las redes de Fabric Primaria o Secundaria.
Temas relacionados