Núcleo de nube privada gestionada
MPC Core es una opción dedicada, basada en VMware Cloud Foundation (VCF), para clientes que necesitan un control total del stack dentro de un entorno gestionado. MPC Core proporciona una infraestructura dedicada con recursos de computación, almacenamiento y red en un Secure Cabinet Express dedicado en un centro de datos Equinix. El servicio MPC Core está basado y alineado con los planos arquitectónicos de VMware Cloud Foundation. La conectividad es compatible con redes de capa 2 y 3 a través de Equinix Fabric o conexiones directas mediante Equinix Metro, Campus y/o Cross Connect. Equinix gestiona la pila completa, incluido VCF, mientras que los clientes configuran su infraestructura dentro de los límites de un despliegue VCF. Los clientes pueden optar por incluir la licencia VCF en el servicio o utilizar la opción BYOL de Broadcom.
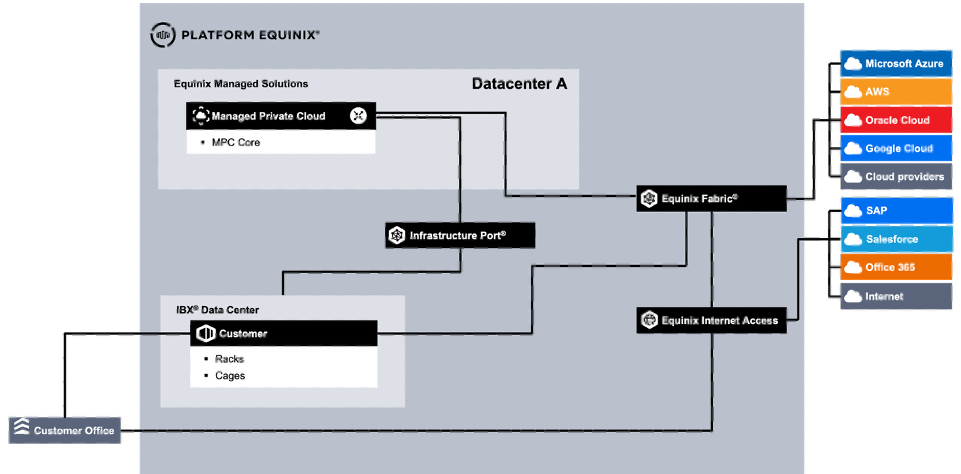
MPC Core está disponible en determinados centros de datos de todo el mundo. Cuando se adquiere en diferentes regiones (AMER, EMEA, APAC), se entrega una implementación independiente para cada región. Cuando se entregan varias implementaciones dentro de la misma región, Active Directory y DNS pueden compartirse entre dichas implementaciones.
MPC Core Blueprints
El diseño del núcleo MPC se basa en el proyecto VCF de VMware Flota VCF en un único emplazamiento con una huella mínima, con HA habilitada en el nivel de los componentes de gestión (implementaciones en clúster). Los componentes de gestión VCF y los recursos del cliente se ejecutan en un único clúster. Este plano proporciona un dominio de gestión que contiene un cluster con un pool de recursos para los componentes de gestión y un pool de recursos para los recursos de cliente.
El dominio de gestión está equipado adicionalmente con VCF Operations HCX para apoyar la migración a la plataforma MPC Core. El dominio de gestión está controlado por Equinix. El conjunto de recursos contiene recursos de clientes y la capacidad disponible depende de los componentes de gestión instalados, el número de hosts del clúster y el tipo de host.
El almacenamiento lo proporciona vSAN. Para la conectividad, un cliente puede utilizar NSX y/o instalar un dispositivo de enrutamiento autogestionado. Un cliente también puede utilizar el servicio Managed Firewall, que es una oferta de cortafuegos gestionada por Equinix que debe solicitarse por separado (Opción Conectividad Managed Firewall).
Una flota **** es una construcción arquitectónica que agrupa varias instancias de VCF para dar soporte a la gestión centralizada y a las operaciones de autoservicio. La primera instancia de MPC Core en un centro de datos es una flota VCF que contiene una única instancia VCF. Este diseño admite hasta 5 clústeres, 100 hosts o 1000 máquinas virtuales por defecto. Cuando se requiere un escalado adicional, es necesario aumentar el tamaño de algunos componentes de gestión, y esta capacidad se deduce de la reserva de recursos del cliente.
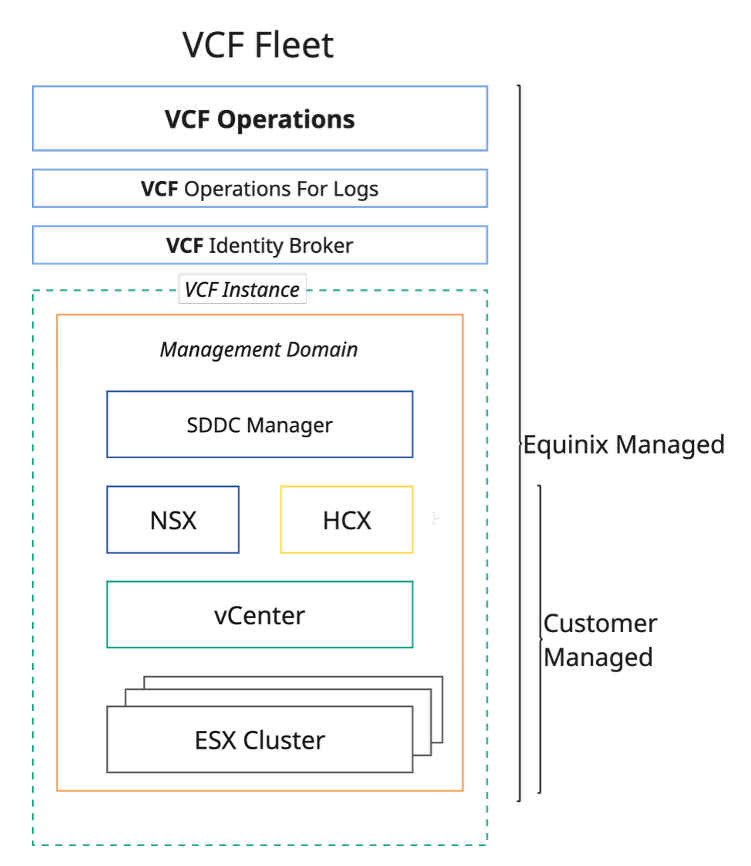
El software instalado incluido en la flota MPC Core VCF en un solo sitio es:
- Instalador VCF
- Gestión de flotas VCF
- Operaciones VCF
- Proxy de nube de operaciones VCF
- vCenter
- Gestores de NSX
- Bordes NSX
- Operaciones VCF para registros
- Agente de identidad VCF
- Operaciones VCF HCX
- Infraestructura de gestión central (servicios de dominio de Active Directory, DNS, autoridad de certificación, supervisión de NTP, Jump Host)
Armario central MPC
MPC Core se entrega desde un centro de datos Equinix en un Secure Cabinet Express dedicado. Dependiendo del tamaño del clúster, un clúster puede abarcar varios armarios. El armario y la alimentación están incluidos en el precio del host. El armario y el acceso son gestionados por Equinix y no están disponibles para los equipos de los clientes. El número máximo de hosts por armario depende de la disponibilidad de energía y del número y consumo de energía de los servidores.
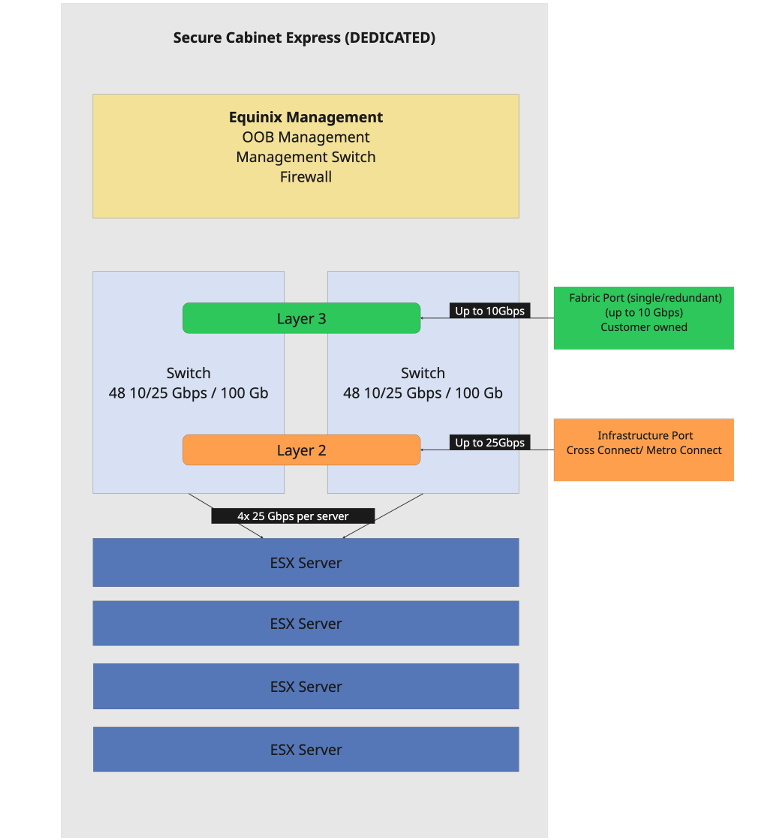
MPC Infraestructura central
Para la gestión de MPC Core, el primer armario está equipado con cortafuegos de gestión, capacidades de gestión fuera de banda (OOB) y conmutadores de gestión. Cada armario incluye dos conmutadores redundantes con 2×48 puertos de 25 Gbps para la conectividad externa y la conectividad del servidor. Cada servidor utiliza dos puertos de cada conmutador para la redundancia. Los conmutadores son gestionados por Equinix. Cuando se despliegan dos armarios, los conmutadores se interconectan de forma redundante entre los armarios, proporcionando 400 Gbps de ancho de banda.
Clúster de núcleo MPC
- Cluster - Un entorno MPC Core incluye una configuración de clúster de al menos siete hosts, en la que seis hosts están disponibles para su uso y un host se reserva para mantenimiento y alta disponibilidad (principio N + 1).
- Alojarse en - MPC Core proporciona un catálogo de tipos de host basado en CPU, núcleos, RAM y almacenamiento.
| Host | Host Type | Billing Type | Description |
|---|---|---|---|
| AHL-16L05V4#4 | Generic Host | Baseline | 16C, 512GB RAM, 4*3.84TB NVME |
| AHL-16L05V6#4 | Generic Host | Baseline | 16C, 512GB RAM, 6*3.84TB NVME |
| AHL-32L05V8#4 | Generic Host | Baseline | 32C, 512GB RAM, 8*3.84TB NVME |
| AHL-32L05V6#8 | Generic Host | Baseline | 32C, 512GB RAM, 6*7.68TB NVME |
| AHL-32L05V8#8 | Generic Host | Baseline | 32C, 512GB RAM, 8*7.68TB NVME |
| AHL-32L05V6#15 | Generic Host | Baseline | 32C, 512GB RAM, 6*3.68TB NVME |
| AHL-32L10V8#4 | Generic Host | Baseline | 32C, 1024GB RAM, 4*15.36TB NVME |
| AHL-32L10V6#8 | Generic Host | Baseline | 32C, 1024GB RAM, 6*7.68TB NVME |
| AHL-32L10V8#8 | Generic Host | Baseline | 32C, 1024GB RAM, 8*7.68TB NVME |
| AHL-32L10V6#15 | Generic Host | Baseline | 32C, 1024GB RAM, 6*15.36TB NVME |
| AHL-64L10V8#8 | Generic Host | Baseline | 64C, 1024GB RAM, 8*7.68TB NVME |
| AHL-64L10V6#15 | Generic Host | Baseline | 64C, 1024GB RAM, 6*15.36TB NVME |
| AHL-64L20V8#8 | Generic Host | Baseline | 64C, 2048GB RAM, 8*7.68TB NVME |
| AHL-64L20V6#15 | Generic Host | Baseline | 64C, 2048GB RAM, 6*15.36TB NVME |
Nota: Los hosts del cluster están comprometidos para todo el periodo de contratación. Cada clúster MPC Core debe utilizar hosts del mismo tipo. Los límites de la plataforma MPC Core se definen a nivel de la solución VCF.
Dimensionamiento de clústeres
El dimensionamiento de un clúster debe basarse en la capacidad de cálculo y la disponibilidad necesarias. Un clúster consta de capacidad consumible neta en el número de hosts (N) e incluye capacidad de reserva para disponibilidad, recuperación y mantenimiento. La capacidad de reserva necesaria depende del tamaño del cluster.
- El tamaño mínimo del clúster es de 7 hosts (N+1).
- Los clusters de más de 15 hosts requieren un segundo host de reserva (N+2).
Tamaños de clúster y capacidad neta
La capacidad de los servidores de repuesto se reserva para garantizar la disponibilidad. Los nodos de repuesto no pueden utilizarse mientras todos los nodos activos permanezcan operativos, y la capacidad que proporcionan no se incluye en la capacidad disponible calculada. El resumen que figura a continuación describe ejemplos de tamaños de clúster, incluidos los tamaños mínimo y máximo, y la capacidad neta utilizable asociada expresada en núcleos de CPU y GB de RAM. La sobrecarga especificada por el proveedor debe restarse de la capacidad del primer clúster. El dimensionamiento aconsejado se basa en las recomendaciones del proveedor:
-
Informática
- N = N+1
- Sobrecarga para el hipervisor
- Máximo 80% de uso medio de CPU y memoria
-
Almacenamiento
- Sobrecarga para la reconstrucción de vSAN y reserva de operaciones
| MPC Core Cluster Size | Hypervisor Server Model | Spare Servers | Usable Capacity | Advised Capacity |
|---|---|---|---|---|
| 7 (6+1) minimum | 16C, 512 GBRAM | 1 | 42 CPU Cores 1350 GBRAM | 39 CPU Cores 1220 GBRAM |
| 32C, 512 GBRAM | 1 | 90 CPU Cores 1350 GBRAM | 77 CPU Cores 1220 GBRAM | |
| 32C, 1024 GBRAM | 1 | 90 CPU Cores 2850 GBRAM | 77 CPU Cores 2450 GBRAM | |
| 64C, 1024 GBRAM | 1 | 180 CPU Cores 2850 GBRAM | 154 CPU Cores 2450 GBRAM | |
| 64C, 2048 GBRAM | 1 | 180 CPU Cores 5700 GBRAM | 154 CPU Cores 4910 GBRAM | |
| 14 (13+1) | 16C, 512 GBRAM | 1 | 182 CPU Cores 5850 GBRAM | 167 CPU Cores 5320 GBRAM |
| 32C, 512 GBRAM | 1 | 390 CPU Cores 5850 GBRAM | 333 CPU Cores 5320 GBRAM | |
| 32C, 1024 GBRAM | 1 | 390 CPU Cores 12350 GBRAM | 333 CPU Cores 10640 GBRAM | |
| 64C, 1024 GBRAM | 1 | 780 CPU Cores 12350 GBRAM | 666 CPU Cores 10640 GBRAM | |
| 64C, 2048 GBRAM | 1 | 780 CPU Cores 24700 GBRAM | 666 CPU Cores 22930 GBRAM | |
| 16 (14+2) | 16C, 512 GBRAM | 2 | 196 CPU Cores 6300 GBRAM | 180 CPU Cores 5730 GBRAM |
| 32C, 512 GBRAM | 2 | 420 CPU Cores 6300 GBRAM | 359 CPU Cores 5730 GBRAM | |
| 32C, 1024 GBRAM | 2 | 420 CPU Cores 13300 GBRAM | 359 CPU Cores 11460 GBRAM | |
| 64C, 1024 GBRAM | 2 | 840 CPU Cores 13300 GBRAM | 717 CPU Cores 11460 GBRAM | |
| 64C, 2048 GBRAM | 2 | 840 CPU Cores 26600 GBRAM | 717 CPU Cores 22930 GBRAM |
Nota: La pila de gestión MPC Core y la sobrecarga VCF (hipervisor, vSAN, NSX) se deducen de la capacidad disponible. El dimensionamiento debe tener como objetivo una utilización máxima del 80% para evitar futuras limitaciones de crecimiento.
Almacenamiento central MPC
En MPC Core, el almacenamiento está incluido en el host y se basa en la tecnología vSAN. La capacidad bruta del clúster está a disposición del cliente. Las políticas de redundancia de datos dependen del número de hosts del clúster. Los gastos generales especificados por el proveedor deben deducirse de la capacidad del clúster. Los clientes pueden seleccionar la configuración RAID que prefieran. vSAN está configurado con cifrado en reposo y cifrado en tránsito. Los clientes son responsables de garantizar que haya suficiente espacio disponible para las operaciones de mantenimiento.
La siguiente tabla presenta la capacidad garantizada basada en seis discos en cada servidor. La capacidad prevista puede ser hasta 1,2 veces superior, en función de las características genéricas de los datos de las máquinas virtuales, la compresibilidad y los datos que no estén cifrados por el cliente, según los promedios de la plataforma y las políticas recomendadas por el proveedor.
| Servers in Cluster | Capacity with Disk Size in TB (3.84) | Capacity with Disk Size in TB (7.68) | Protection |
|---|---|---|---|
| 4 | 24.6 | 53.43 | RAID-5 (Single Parity / 2+1 Scheme / 50% RAID overhead) |
| 5 | 34.09 | 73.47 | RAID-5 (Single Parity / 2+1 Scheme / 50% RAID overhead) |
| 6 | 52.29 | 112.19 | RAID-5 (Single Parity / 4+1 Scheme / 25% RAID overhead) |
| 7 | 53.06 | 113.53 | RAID-6 (Dual Parity / 4+2 Scheme / 50% RAID overhead) |
| 8 | 62.55 | 133.56 | RAID-6 (Dual Parity / 4+2 Scheme / 50% RAID overhead) |
| 9 | 72.03 | 153.59 | RAID-6 (Dual Parity / 4+2 Scheme / 50% RAID overhead) |
| 10 | 81.51 | 173.62 | RAID-6 (Dual Parity / 4+2 Scheme / 50% RAID overhead) |
| 11 | 90.99 | 193.65 | RAID-6 (Dual Parity / 4+2 Scheme / 50% RAID overhead) |
| 12 | 100.47 | 213.68 | RAID-6 (Dual Parity / 4+2 Scheme / 50% RAID overhead) |
| 13 | 109.95 | 233.71 | RAID-6 (Dual Parity / 4+2 Scheme / 50% RAID overhead) |
| 14 | 119.43 | 253.74 | RAID-6 (Dual Parity / 4+2 Scheme / 50% RAID overhead) |
| 15 | 128.91 | 273.77 | RAID-6 (Dual Parity / 4+2 Scheme / 50% RAID overhead) |
Licencias de VMware
MPC Core admite el uso de licencias VCF propiedad del cliente de Broadcom/VMware o licencias proporcionadas por Equinix. El uso de licencias BYOL (Bring-Your-Own-License) está sujeto a los requisitos de cumplimiento de Broadcom. Para utilizar licencias BYOL para una instancia MPC Core, las licencias deben compartirse con Equinix e incluirse en los informes de Equinix a Broadcom.
Conectividad de núcleo MPC
Para integrar MPC Core en las arquitecturas de nube (multi) del cliente, puede conectarse a diferentes opciones de conectividad. Hay que tener en cuenta dos aspectos a la hora de determinar cómo se conecta el MPC Core a los recursos externos:
- El tipo de conectividad (capa 2 o capa 3)
- El enrutamiento (proporcionado por Equinix o por el cliente)
La conectividad externa de MPC Core admite lo siguiente:
-
Capa 3 basada en BGP a. Enrutado Equinix mediante Equinix Fabric™, Equinix Cloud Router™ o Equinix Network Edge™ b. Enrutado proporcionado por el cliente mediante Cross Connect™, Metro Connect™ o Infrastructure Port™.
-
Capa 2 a través de Infrastructure Port™, Cross Connect™ o Metro Connect™. a. No redundante, utilizando una única conexión b. Redundante, utilizando conexiones duales basadas en LACP no a través de Fabric
Tanto las conexiones de capa 2 como las de capa 3 son compatibles con una única implementación de MPC Core.
| Product | Layer-3 | Layer-2 | Layer-2 redundant with LACP |
|---|---|---|---|
| Fabric | X | X | - |
| Network Edge | X | X | - |
| Cloud Router | X | X | - |
| Cross Connect | X | X | X |
| Metro Connect | X | X | X |
-
Conectividad Enrutada - En esta variante, la solución de red NSX incluida en el conjunto VCF se utiliza como función de enrutamiento y red virtual. Equinix instala dos dispositivos NSX Edge, de tamaño grande, en el conjunto de recursos del cliente y los configura con BGP proporcionado por el cliente. Toda la conectividad de capa 3 termina en el enrutador NSX Edge. El Edge se conecta utilizando dos VLAN para la conectividad externa. Las conexiones de capa 2 se terminan en un grupo de puertos en vCenter. Con la conectividad enrutada, las funciones de red disponibles se limitan al cortafuegos sin estado.
Cuando se requiera un cortafuegos de estado o un cortafuegos distribuido, se pueden solicitar opciones de servicio adicionales, como el cortafuegos de puerta de enlace y el cortafuegos distribuido.
-
Conectividad Cliente Enrutado - En esta variante, el cliente proporciona un dispositivo de enrutamiento con licencia. Los componentes de NSX se siguen instalando según lo requiera la implantación de VCF. Todas las conexiones externas enrutadas terminan en el dispositivo de enrutamiento proporcionado por el cliente. El dispositivo se conecta utilizando dos VLAN para la conectividad externa. Las conexiones de capa 2 se terminan en un grupo de puertos en vCenter.
Con el enrutamiento proporcionado por el cliente, el cortafuegos distribuido puede utilizarse como una característica opcional, con licencia a través de la opción de servicio.
-
Direccionamiento IP y VLAN - Equinix utiliza rangos de IP y VLAN predeterminados para la instancia MPC Core. Los clientes pueden proporcionar sus propias direcciones IP y VLAN. Si se produce un conflicto, Equinix asignará un rango alternativo en consulta con el cliente.
El servicio se configura utilizando IPv4. Los clientes pueden utilizar IPv4 e IPv6 para sus cargas de trabajo si son compatibles con la solución VCF de VMware.
Funciones de red de NSX
VCF y NSX proporcionan un catálogo de funciones de red. Algunas funciones se incluyen como parte de la licencia de VCF, mientras que otras requieren licencias adicionales por núcleo.
| Type | Description | Edge Cluster Required | Extra License |
|---|---|---|---|
| Edge | Basic network functions | Yes | No |
| Gateway Firewall | Stateful Firewall | Yes | Yes |
| Distributed Firewall | East‑West protection | No | Yes |
Para utilizar las funciones de red de NSX, debe seleccionarse la opción Connectivity Routed. Con esta configuración, las funciones NSX pasan a estar disponibles para el cliente. Los Edge se despliegan en el clúster del cliente y consumen recursos de dicho clúster. El tipo de Edge determina las funciones y el rendimiento disponibles.
| Edge Type | Size | Use Case |
|---|---|---|
| Edge Medium | Two edges in HA with 4 vCPU, 16 GB RAM, 300 GB storage each | - L2–L4 features - Expected bandwidth up to 2 Gbps - L3–L4 Firewall - NAT - Routing |
| Edge Large | Two edges in HA with 8 vCPU, 16 GB RAM, 300 GB storage each | - L2–L4 features - Expected bandwidth up to 10 Gbps - L3–L4 Firewall - NAT - Routing - Bridging - VPN - TLS Inspection |
| Edge X‑Large | Two edges in HA with 16 vCPU, 32 GB RAM, 300 GB storage each | - L2–L7 features - L3–L4 Firewall - NAT - Routing - Bridging - VPN - TLS Inspection - L7 Access Profile (URL filtering) - IDS / IPS - Malware prevention |
El cortafuegos de puerta de enlace **** proporciona un cortafuegos de capa 2-7 definido por software diseñado para proteger las cargas de trabajo virtualizadas en una nube privada. Admite un cortafuegos de estado con funciones de prevención de amenazas. La protección avanzada frente a amenazas (ATP) combina múltiples tecnologías de detección, entre las que se incluyen la detección y prevención de intrusiones (IDS/IPS), el sandboxing de red y el análisis del tráfico de red (NTA), junto con los motores de agregación, correlación y contexto de la detección y respuesta de red (NDR). Esta función requiere licencias adicionales que pueden solicitarse a través de la opción de servicio Gateway Firewall. El número de licencias necesarias depende del tamaño del Edge.
| Type | Number of Licenses |
|---|---|
| Edge Medium | 24 |
| Edge Large | 48 |
| Edge X‑Large | 96 |
El cortafuegos distribuido **** proporciona un cortafuegos de capa 2-7 definido por software diseñado para proteger cargas de trabajo virtualizadas, contenedores y servidores Bare Metal en una nube privada. Puede aplicarse en cada carga de trabajo para segmentar el tráfico este-oeste y evitar el movimiento lateral de amenazas. Para utilizar el cortafuegos distribuido, debe seleccionarse la opción de servicio Cortafuegos distribuido (DFW). El número de licencias necesarias se basa en el tamaño del cluster en núcleos, y cada núcleo debe tener licencia.
Acceso al núcleo MPC
MPC Core proporciona múltiples interfaces de usuario para las operaciones:
- Operaciones VCF
- Operaciones VCF para registros
- NSX
- vCenter
- Operaciones VCF HCX (disponible sólo durante la migración)
Para la gestión de identidades y accesos, MPC Core incluye un agente de identidades que debe conectarse al Directorio Activo del cliente a través de LDAP seguro. Los usuarios y grupos del Directorio Activo del cliente se utilizan para asignar permisos dentro del MPC Core. Los grupos definidos por el cliente se asignan a roles predefinidos como parte del proceso de cumplimiento. Se pueden solicitar cambios en el modelo de permisos a través de una solicitud de servicio.
Permisos
MPC Core distingue tres tipos de permiso:
| Name | Description |
|---|---|
| Restricted | Only Equinix has access and determines the configuration required for service availability. |
| Limited | Only Equinix has access, but the customer can request parameter changes via a service request. |
| Free | Functions are available to the customer through the consoles. |
Integración de aplicaciones
Para algunas aplicaciones o integraciones, se requiere acceso al entorno de gestión. Entre los casos de uso más comunes se incluyen:
- Integración para copias de seguridad (Veeam, CommVault, Rubrik)
- Integración para herramientas de DR (Zerto, Veeam Replication)
- Integración para soluciones VDI (Omnissa, Citrix)
- Integración para automatización CI/CD e infraestructura como código (Terraform, Ansible)
Para las integraciones de aplicaciones, las cuentas de servicio del Directorio Activo del cliente se asignan a roles predefinidos en MPC Core.
Ampliación del servicio
La ampliación del servicio MPC Core puede realizarse de varias maneras:
- Añadir más servidores iguales a los clústeres existentes
- Ampliación del número de clústeres en la instancia, hasta un máximo de 5 clústeres por instalación
- Iniciar una nueva instancia VCF

Cuando un clúster informático requiere una fuerte separación de recursos, se puede crear una segunda instancia dentro de la misma flota. La instancia VCF adicional incluye su propia pila de gestión.

Descripción del servicio
Opciones de servicio
MPC Core incluye varias opciones de servicio que se solicitan por separado.
Copia de seguridad y restauración
La copia de seguridad y la restauración de los recursos MPC se proporcionan a través del servicio de copia de seguridad privada gestionada (se solicita por separado). El servicio incluye la copia de seguridad de los datos de las máquinas virtuales o de los datos de las aplicaciones mediante una plataforma de copia de seguridad compartida.
Licencias de software
Está disponible un catálogo de ISOs de software sin licencia para MPC. Este catálogo enumera el software que se puede utilizar en las máquinas virtuales que se ejecutan en un despliegue de MPC Core. El software con licencia puede adquirirse a través del producto Licencias de software. Tras la adquisición, las ISO estarán disponibles en el catálogo.
Los clientes también pueden traer sus propias licencias de software. Al utilizar Bring Your Own License (BYOL), se debe validar el cumplimiento de los términos de licencia del proveedor del software.
Para todas las licencias, el cliente es responsable de cumplir los requisitos de conformidad del proveedor de software.
Plan de asistencia
El plan de asistencia ofrece un servicio opcional que cubre las solicitudes de servicio adicionales y otros servicios como la asistencia ampliada, los informes adicionales y la asistencia de diseño.
El plan de asistencia Premier de Managed Solutions **** es un programa de prepago que permite la compra de bloques mensuales o anuales (pago único) de horas de asistencia con descuento. Las horas de soporte se consumen en incrementos de quince (15) minutos.
Sin un plan de asistencia Premier de Managed Solutions de prepago, la asistencia se cobra a la tarifa horaria estándar del servicio de asistencia Premier por hora (tarifa horaria estándar). Las horas de asistencia se calculan en incrementos de quince (15) minutos.
| PURCHASE UNIT | TYPE | CHARGE TYPE | UOM | ORDERING AND BILLING |
|---|---|---|---|---|
| Technical Support Plan | Monthly | Baseline | hour | Monthly reservation of hours for technical support |
| Technical Support Plan | Annual | Baseline | hour | Yearly reservation of hours for technical support |
El plan no está designado a un producto Managed Solutions específico, sino que se aplica a todos los productos Managed Solutions adquiridos.
Si se han consumido todas las horas del plan, las horas adicionales se cobrarán según la tarifa horaria estándar del "Servicio de asistencia Premier".
Las horas mensuales o prepagadas del Plan de asistencia Premier de Managed Solutions no se acumulan y se pierden si no se utilizan. El uso que supere la cantidad precomprada se facturará según la tarifa horaria habitual del "Servicio de asistencia Premier", a menos que se solicite una actualización.
El plan es específico para cada país y no puede vincularse a un centro de datos IBX concreto.
Apoyo a la migración
Para migrar cargas de trabajo a MPC Core desde entornos locales, otras instalaciones de Colocation o plataformas VMware basadas en nubes públicas (como AWS u OCVS), Equinix proporciona herramientas de migración que permiten la migración de cargas de trabajo de autoservicio sin necesidad de refactorizar las aplicaciones. Las herramientas son compatibles con las cargas de trabajo que se ejecutan en vSphere, Hyper-V y otras plataformas de virtualización mediante el uso de varios métodos de migración, incluida la migración a nivel de hipervisor y del sistema operativo huésped.
Para permitir la migración para cargas de trabajo vSphere, el cliente recibe un dispositivo VCF Operations HCX que se instala en el entorno del cliente y se empareja con el entorno MPC Core durante la configuración. La herramienta admite la replicación asíncrona.
-
Migración vMotion - Este método utiliza el protocolo VMware vMotion para mover una máquina virtual a un sitio remoto.
- Diseñado para mover una sola máquina virtual a la vez
- Migra el estado de la máquina virtual sin interrupción del servicio
- Requiere una capacidad de rendimiento de 250 Mbps o superior
- Latencia < 150 ms
- MTU mínima: 1150
- Máximo de máquinas virtuales por operación 1
-
Migración en frío - Este método utiliza el protocolo NFC de VMware y se utiliza automáticamente cuando se apaga la máquina virtual de origen.
- Requiere una capacidad de rendimiento de 250 Mbps o superior
- Latencia < 150 ms
- MTU mínima: 1150
- Máximo de máquinas virtuales por operación 1
-
Migración masiva - Este método utiliza VMware vSphere Replication para mover las máquinas virtuales al sitio de destino.
- Diseñado para mover varias máquinas virtuales en paralelo
- Puede programarse para que finalice a una hora predefinida
- La máquina virtual funciona en el origen hasta que comienza la conmutación por error (interrupción del servicio similar a un reinicio)
- Requiere una capacidad de caudal de 50 Mbps o superior
- Latencia < 150 ms
- MTU mínima: 1150
- Admite hasta 1000 migraciones simultáneas (en función del tamaño del dispositivo HCX Manager)
-
Replication Assisted vMotion (RAV) - Replication Assisted vMotion combina las ventajas de la migración masiva (operaciones paralelas, resistencia, programación) con vMotion (migración de estado sin tiempo de inactividad).
- Requiere una capacidad de rendimiento de 250 Mbps o superior
- Latencia < 150 ms
- MTU mínima: 1150
- Admite hasta 1000 migraciones simultáneas (en función del tamaño del dispositivo HCX Manager)
Una migración sencilla requiere circuitos Fabric dedicados o VLAN en un Cross-Connect. Una vez completada la migración, se elimina la herramienta de migración.
Demarcación de servicios
A continuación se muestra la delimitación de responsabilidades entre el cliente y Equinix.
| AREA | RESPONSIBILITY | DETAILS |
|---|---|---|
| Customer Data | Customer | Data governance and data access rights management |
| Account & Access Management | Customer | User account management, identity MFA/ID, multifactor authentication |
| Data Protection | Customer | Antivirus, client & server data encryption, network traffic encryption |
| Applications | Customer | Functional and technical application management |
| Databases | Customer | MySQL, Microsoft SQL, Oracle, PostgreSQL |
| Middleware | Customer | Enterprise Service Bus, Tomcat, .NET Framework |
| Operating System | Customer | Windows & Linux OS management |
| Compute Virtualization | Equinix Managed Solutions | VMware ESXi hypervisor, vCenter configuration |
| Network Virtualization | Equinix Managed Solutions | VMware NSX platform, NSX configuration (firewall, edges), connectivity |
| Compute | Equinix Managed Solutions | Dedicated compute resources |
| Storage | Equinix Managed Solutions | vSAN storage, vSAN configuration |
| Datacenter Connect | Equinix Managed Solutions | Redundant switches |
| Datacenter Facilities | Equinix Managed Solutions | Secure cabinet express, power, cooling, access control, physical security |
Unidades de compra
El servicio MPC se cobra mensualmente en función de los valores Baseline o Baseline con tipos de cargo Overage.
- Línea de base - El volumen específico de la Unidad de Medida (UM) del servicio tal y como se define en el pedido.
- Overage - La cantidad de servicio consumida por el cliente que excede el volumen base contratado.
Catálogo de unidades de compra
| Category | Purchase Unit | UOM | Install Fee | Billing Method | Overage |
|---|---|---|---|---|---|
| MPC Service | Connectivity | Each | No | Baseline | No |
| MPC Compute | <Host Type> | Host | Yes | Baseline | No |
| MPC Service Option | Gateway Firewall <n> Size Edge | Edge | No | Baseline | No |
| Distributed Firewall <n> Cores | Host | No | Baseline | No |
- Consulte la opción de servicio Gateway Firewall para conocer el número de núcleos 2) El número de núcleos se aplica al host utilizado en el clúster
Funciones y responsabilidades
A continuación se describe cómo se dividen las responsabilidades entre Equinix y el cliente a lo largo del cumplimiento del servicio, la incorporación y las operaciones en curso.
Aprovisionamiento de inquilinos
| ACTIVITIES | EQUINIX | CUSTOMER |
|---|---|---|
| Schedule / execute project kickoff meeting | RA | CI |
| Schedule / execute customer onboarding | RA | CI |
| Delivery of the hosts in a cluster according to the design blueprint and order | RAC | I¹ |
| Delivery of the storage capacity in accordance with design | RAC | I¹ |
| Delivery of the connectivity in accordance with the order | RAC | I¹ |
| Delivering agreed network functionality in accordance with design (optional) | RAC | C |
| Set up service accounts for selected applications | RAC | C |
| Delivery of the MPC Operational Console | RAC | I¹ |
| Delivery of user groups according to the customer | RAC | I¹ |
Aceptación en servicio
Una vez finalizadas las actividades de onboarding, las pruebas confirmarán que el producto se ha entregado correctamente y está listo para su facturación.
| ACTIVITIES | EQUINIX | CUSTOMER |
|---|---|---|
| Test access to MPC documentation on docs.equinix.com | CI | RA |
| Test access to the different consoles for the different groups | CI | RA |
| Confirm MPC fulfillment based on provided evidence | CI | RA |
| Check handover documentation | CI | RA |
| Set product as enabled for customer internal systems | RA | I |
Operativo
Una vez habilitado el servicio de nube privada gestionada, se abordan los siguientes puntos operativos:
| ACTIVITIES | EQUINIX | CUSTOMER |
|---|---|---|
| Technical management of the service (overall) | RAC | I* |
| Patching and LCM of software: VCF Operations, vSphere, NSX, vSAN, HCX | RAC | I* |
| MPC infrastructure monitoring and maintenance | RA | I |
| Keep applications with integration into MPC compliant with MPC Core versions | I* | RAC |
| Functional management of the customer environment within the service (overall) | I¹ | RAC |
| Manage capacity of the compute and storage in the cluster | I¹ | RAC |
| Create, import and manage VMs and vApps | I¹ | RAC |
| Keep VM‑tooling up to date | I¹ | RAC |
| Scale VMs up and down | I¹ | RACI |
| Manage VM snapshots | RACI | |
| Manage access to VMs with console | RACI | |
| Request performance statistics | RACI | |
| Create and fill “Library” with customer’s own ISO/OVA files | RACI | |
| Separate or group VMs for availability or performance | I¹ | RAC |
| NFV: Virtual L2 networks | I¹ | RAC |
| NFV: Standard firewalling | I¹ | RAC |
| NFV: Routing (static) | I¹ | RAC |
| NFV: Routing (dynamic OSPF / BGP) | I¹ | RAC |
| NFV: NAT | I¹ | RAC |
| NFV: DHCP | I¹ | RAC |
| NFV: Load Balancing | I¹ | RAC |
| NFV: VPN (IPsec, Client) | I¹ | RAC |
| Setup and manage scripting & automation capabilities | RACI |
Nota: RACI son las siglas en inglés de Responsable, Contable, Consultado e Informado.
I¹ Informar sólo es obligatorio para las tareas que repercuten en el funcionamiento del entorno del usuario.
I² Informar sólo es obligatorio para tareas que tengan un impacto en el funcionamiento y/o la gestión del servicio.
Gestión de incidentes
La gestión de incidencias se incluye como parte del servicio de asistencia. Todos los incidentes se gestionan en función de la prioridad. La prioridad se determina después de que se notifique un incidente y Equinix lo evalúa basándose en la información proporcionada.
| Priority | Impact / Urgency | Description |
|---|---|---|
| P1 High | Unforeseen unavailability of a service or environment delivered and managed by Equinix, in accordance with the service description, due to a disruption. The customer cannot fulfill obligations towards its own users. The customer experiences direct demonstrable impact due to unavailability of this functionality. | The service must be restored immediately; production environments are unavailable with platform‑wide disruptions. |
| P2 Medium | The service does not offer full functionality, or operates with partial functionality or reduced performance, resulting in user impact. The customer experiences direct demonstrable impact due to limited availability of the functionality. | The service must be repaired the same working day; the management environment is not available. |
| P3 Low | The service functions with limited availability for one or more users, and a workaround is in place. | The repair timeline is determined in consultation with the reporting person. |
Nota: Esta clasificación no se aplica a las interrupciones causadas, por ejemplo, por aplicaciones específicas del usuario, acciones del usuario o dependientes de terceros. Los incidentes pueden enviarse a través del Portal del Cliente en la sección Managed Solutions. Los incidentes P1 deben enviarse por teléfono.
Solicitudes de servicio
Las solicitudes de servicio se utilizan para informar de problemas de servicio o para solicitar asistencia con cambios de implementación o configuración. Los cambios de configuración estándar pueden solicitarse a través del portal de autoservicio MPC como una solicitud de servicio. La asistencia está disponible 24×7×365. Existen dos tipos de solicitudes de servicio:
- Incluido - Solicitudes de servicio que están dentro del alcance del servicio y no incurren en cargos adicionales.
- Adicional - Solicitudes de servicio que están fuera del alcance del servicio e incurren en cargos adicionales.
| Request Name | Included / Additional |
|---|---|
| Create a new permission group | Included |
| Remove a permission group | Included |
| Add VLAN to MPC Core instance | Included |
| Delete a VLAN from MPC Core | Included |
| Create Edge Cluster | Additional |
| Delete Edge Cluster | Additional |
| Resize Edge Cluster | Additional |
Los cambios no incluidos en la lista anterior pueden solicitarse seleccionando Cambiar en el módulo de solicitud de servicio. Equinix realizará un análisis del impacto para determinar la viabilidad, el coste y el plazo de entrega. Los cargos relacionados con las solicitudes de servicio se deducen del saldo del Plan de Asistencia Premier **** . Si el saldo es insuficiente, los cargos se facturan a la tarifa vigente. Las solicitudes que afecten a la capacidad de base, a las cantidades solicitadas o a cualquier cambio que afecte a la tarifa mensual del servicio deberán solicitarse a través del equipo de ventas de Equinix.
Informes
Como parte del servicio, los clientes reciben informes mensuales que cubren las incidencias planteadas frente a los parámetros del SLA y la capacidad por clúster.
Niveles de servicio
El Acuerdo de Nivel de Servicio (SLA) define los niveles de rendimiento medibles asociados con el servicio MPC y especifica las soluciones en caso de que Equinix no cumpla estos niveles. Los créditos de servicio descritos en la Política de Producto son el remedio exclusivo para los incumplimientos del SLA.
El SLA de Support se aplica al registro y resolución de incidencias.
| Priority | Response Time¹ | Resolution Time² | Execution of Work | SLA³ |
|---|---|---|---|---|
| P1 | < 30 min | < 4 hours | 24x7 | 95% |
| P2 | < 60 min | < 24 hours | 24x7 | 95% |
| P3 | < 120 min | < 5 days | 24x7 | 95% |
¹ El tiempo de respuesta se mide desde el momento en que se envía un ticket de problema hasta que un especialista de Equinix Managed Solutions proporciona una respuesta formal.
² El tiempo de resolución se mide desde la creación del ticket hasta su cierre, cancelación o entrega al soporte de IBX.
² El SLA se aplica al tiempo de respuesta, los detalles sobre el SLA se pueden encontrar en la Política de Producto.
El nivel de disponibilidad **** para el servicio MPC refleja la disponibilidad de un clúster. El servicio se considera no disponible cuando la infraestructura gestionada por Equinix hace que el clúster de carga de trabajo entre en un estado de error que interrumpe los servicios al cliente.
| AVAILABILITY SERVICE LEVEL | DESCRIPTION |
|---|---|
| 99.95%+ | Less than 22 minutes of unavailability per calendar month |
Los términos de crédito de servicio para la disponibilidad están documentados en la Política de Producto. La disponibilidad no incluye las actividades de restauración de datos. Cuando se contrata Managed Private Backup, los clientes pueden restaurar los datos a través de su consola operativa. Cuando no se contrata Managed Private Backup, los clientes son responsables de restaurar sus propios datos.