
Overview of Geo-Redundancy with Network Edge
This document discusses design considerations for anyone interested in geo-redundant solutions on Network Edge. We will walk through a couple of use cases starting with a simple example and progressively layering in more options. There is not a one-size-fits-all solution that works for everyone; you will have to make decisions that best fit your requirements.
Cloud-to-Cloud Routing
In this common Network Edge use case, the Network Edge devices are simply routing between two cloud service providers (CSPs).

You have the option to add local resiliency by adding another Network Edge router and redundant connections to the CSPs in the same metro. Local redundancy protects against a local hardware failure since the redundant devices are placed in different compute planes. You also have the flexibility to create redundant virtual circuits from the redundant Network Edge devices to the CSPs depending on their risk tolerance.

However, locally redundant VNFs and connections don’t protect against an outage that affects all local devices, such as a fire that could take out devices for an extended period, or even an infrastructure upgrade. For this level of resiliency, geo-redundancy should be considered. Building on the use case from above, an additional Network Edge router is deployed in a different NE metro. Typically, this new device would be in the same region, but this is not a requirement because Equinix Fabric allows connectivity between metros around the world.
Local redundancy combined with geo-redundancy provides maximum protection from both local hardware failures in a metro as well as issues (fire, natural disaster, etc.) affecting all devices in the metro.
Cloud On-Ramp with Cloud-to-Cloud Routing
In this use case, SD-WAN traffic from branch offices is being aggregated and on-ramped to the clouds. Like the previous use case, it also provides for cloud-to-cloud routing.

Customers commonly deploy SD-WAN aggregation on-ramps in multiple locations to improve the user experience by reducing latency while avoiding having to trombone traffic across long distances.

In addition to providing for a better user experience, this architecture may also provide for geo-redundancy: in the event of an outage that affects the entire Silicon Valley deployment, SD-WAN traffic will be re-routed to Ashburn. Multi-cloud traffic can still take place through the available metro.
If you want geo-redundancy and have only one operational metro (or have two or more metros and want to add a new metro), one option is to mirror the existing metro(s). In this example a new site is added in Chicago.

Equinix offers multiple options for access-layer connectivity. For example, you may be using a remote Fabric port (also known as BYOC) to connect to a service provider in Silicon Valley. To provide access-layer connectivity the geo-redundant site in Chicago, you have multiple options:
-
Use a new local network provider in the new metro(s) – either through BYOC or a provider already on the Fabric. With BYOC, you connect to a local network provider on the Fabric via a remote port. This process can take several days to complete.
-
Create point-to-point VCs from the new metro (Chicago) back to an existing site (Silicon Valley). Typically, you would choose this option as either a temporary geo-redundant solution for situations such as a planned maintenance affecting the primary metro; or as a “cold standby” solution where the geo-redundant metro only exists in the event the primary metro is not available. This is not as common because you will likely need to manually redirect traffic from the primary metro to the redundant metro. Additional concerns around operational requirements for address space management, application flows, and what mechanisms exist to maintain network continuity make this more operationally complex.
-
Use multipoint-to-multipoint connectivity to share the service provider connection across metros. This is especially helpful in creating a full meshed topology across multiple metros. The benefit to this approach is that multiple connections are built to extend the provider connection to multiple metros. Considerations include available address space limitations on existing circuits, and what options your provider offers to share the connection across Equinix Fabric. Due to the requirements set by the provider, you will need to evaluate you options because they vary among providers. For maximum resiliency, the suggested best practice is to create two or more meshes from separate providers in different markets.
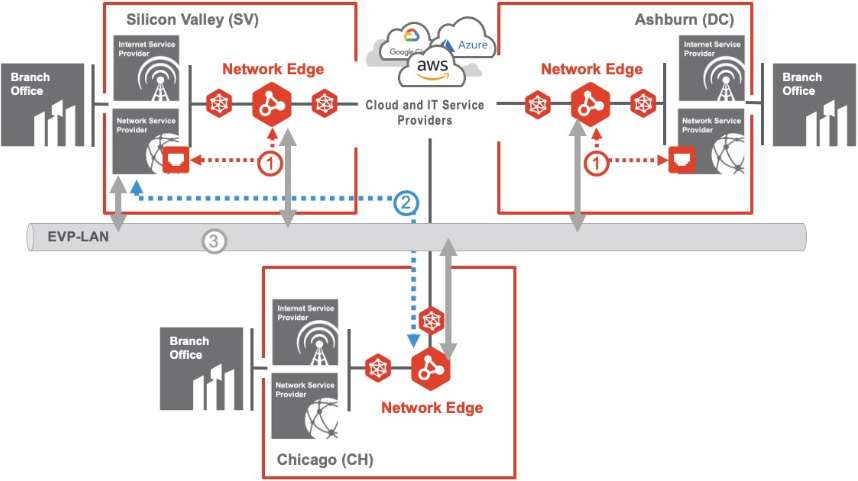
In these examples, if the NNetwork Edge devices in one market become unavailable, the SD-WAN traffic will reroute through a new market. Users and applications may experience increased latency, depending on the existing connections and where they are located.
When deploying geo-redundant sites, you should also consider cloud connections. For example, if the Silicon Valley deployment connects locally through AWS Direct Connect to the AMER West region, it is common for the Ashburn site to connect to the AWS AMER East region. This is typical due to customers preferring the lowest latency connections available in the same region. Therefore, an important consideration for geo-redundancy is how to maintain the cloud provider access in the event of a metro failure of Network Edge. This will vary based on your preference and requirements, but these connections are often maintained through one of four methods:
-
You have transit connectivity across regions in the cloud provider. In the example above, if Silicon Valley were unavailable, then network traffic in DC would be routed to the AMER West region across the AWS backbone.
-
You have transit connectivity through Equinix Fabric. In the example above, you could choose to build your cloud connections across the Equinix Fabric so that traffic in DC would connect to the AWS AMER West region. This is common in deployment where you do not have transit connectivity across the cloud provider’s backbone.
-
You use the Internet (DIA) for transit connectivity. This is common where SD-WAN gateways are deployed, and the Internet is being used as the underlay for transit connectivity between sites. You may find this preferable because of your latency budget and business requirements.
-
You use some combination of all of the above. The methods above are not mutually exclusive. In fact, they can be used interchangeably depending on regional or national boundaries and their risk tolerance.
Colocation
Many customers also have physically deployed kit co-located in an Equinix IBX. Building on the use cases above, connections can be built to incorporate these sites as part of a geo-redundant architecture. It is common for customers to augment their existing Network Edge deployments by sending traffic to their co-located sites. Many times, these sites are used to provide business continuity as part of bigger network resiliency initiative.

If you require DC to access corporate applications located in SV, you could:
-
Use a point-to-point VC from the SV colocation shared port through the Fabric to the Network Edge device in DC. You should evaluate whether your existing address space will accommodate this connectivity.

-
Use a multipoint-to-multipoint connection from the SV colocation shared port through the Fabric to the Network Edge device in DC. This approach is easier than using point-to-point connections (P2P) to create a full mesh across several sites. Similar to the example above, you should evaluate whether your existing address space allows for this connectivity option.

Summary
Equinix offers many levels of redundancy to give you flexibility in choosing the best solution based on risk tolerance and business continuity. Local redundancy mitigates against a single hardware failure in the Network Edge infrastructure. VC redundancy protects against single path failures due to issues in the underlying transport infrastructure. You have the option to add redundant VCs after the initial deployment which allows the architecture to evolve as business requirements do. Geo-redundant architectures provide resiliency at the metro level and mitigate issues when an entire metro is at risk.
For the greatest resilience, you should consider locally redundant devices combined with geo-redundant deployments. This approach mitigates both single failures in the infrastructure within a metro as well as any risks associated if an entire metro were to go offline. Combining this with diversified network providers and cloud providers with fully meshed multipoint connectivity is considered a best practice for anyone who cannot afford any downtime.
