High Availability Options in Network Edge
This topic explains two options for deploying highly available network services in Network Edge: redundant devices and device clustering.
Network Edge is a Network-as-a-Service (NaaS) offer that allows rapid deployment of Virtual Network Functions (VNFs) that are attached to the Equinix Fabric. This platform allows customers to quickly create virtual connections to providers, other Equinix customers, or their own physical deployments in an Equinix IBX. Network Edge is a popular option when speed to deployment is paramount without a large CAPEX procurement process, and allows customers a more flexible approach to meet their network service challenges in multi-cloud environments.
Network Edge deployment scenarios are becoming more complex as customers find innovative ways to leverage virtual networking constructs to solve their business problems. This includes deploying VNFs in the same highly available and resilient manner that is asked of the physical networking components and is difficult to do in public cloud providers. Two options for deploying highly available network services in Network Edge are described below.
Redundant Devices (Active/Active)
The first High Availability (HA) option released in Network Edge was the ability to deploy VNFs with redundancy. When creating a device in the Equinix portal, HA is the middle option labeled With a Secondary High Availability Device.
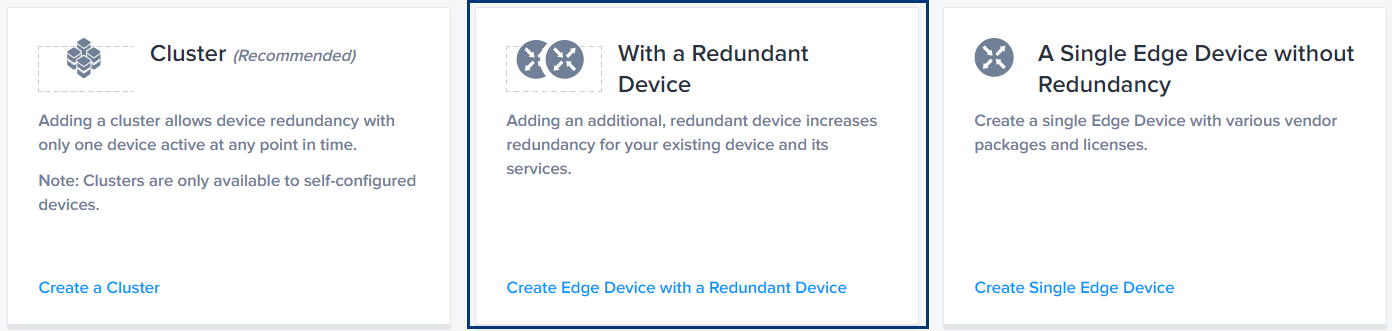
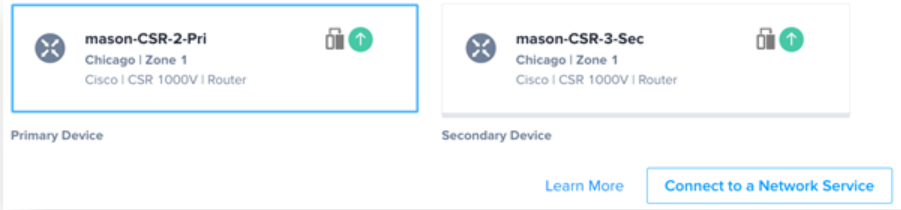
Choosing this option creates two devices that are logically grouped together in the Equinix Portal. The devices can be installed in the same Equinix metro (most common) or they can be deployed in different metros (for example, Chicago and Dallas). One VNF is designated as Primary and the other is Secondary. Redundant devices can only be deployed in pairs and support manually configured device linkages that enable additional features that are vendor-specific.
Both devices will have uniquely addressed interfaces, and both will actively forward traffic (Active/Active). For management and licensing, redundant devices are treated as two independent devices by Network Edge. No other device linkages are created at VNF inception.
Equinix will install the VNFs on separate hardware planes to minimize the risk of a single hardware failure affecting both devices. If the redundant devices are deployed in different metros, then this is implied.
Redundant devices in Network Edge are depicted in the Equinix Portal as shown in Figure 2. This ensures a consistent methodology as services and connections are created on the redundant devices. Virtual connections can be created to one or both devices.
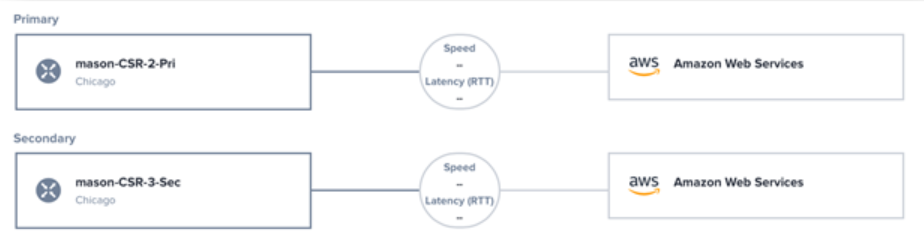
Redundant devices are useful for customers that require two actively forwarding data planes (Active/Active) on separate hardware stacks. It's common to configure additional resiliency features (e.g., HSRP, GLBP, VRRP, etc.) on the devices to create a redundant data plane. As noted above, the device linking required for these options must be built manually.
In summary, the Network Edge redundant device deployment option is a solution where customers would deploy two devices working together to ensure a consistent data plane experience. This is achieved through routing (multiple equal cost paths) or additional configuration of L3 resiliency features like HSRP, etc.
A redundant pair with a newer software version (non-retired version) can be added to the primary device. However, having two devices in a redundant pair with different software versions might affect performance. We recommend that you update the software version for your primary device.
Device Clustering (Active/Standby)
Clustering is a newer option for Network Edge that makes use of vendor-specific features to allow more robust HA options. Clustering creates two VNFs that are treated by the Equinix portal as one shared logical construct that are deployed in an Active/Passive format. This is different from the Redundant Device option where the portal treats the devices as two independent and separate devices.
With clustering, the two VNFs are created in separate hardware planes but share the same management address. One VNF is designated as “Node 0” and the other as “Node 1” and can only be deployed in pairs. Currently clustering is supported for Juniper, Palo Alto Networks, and Fortinet. Clustering is only supported with Self-Configured devices using the Bring Your Own License (BYOL) option.
During the VNF creation process, Network Edge orchestration builds the required device linkages between Node 0 and Node 1. These linkages are based upon the vendor’s requirements. Unlike the Redundant Devices option where these linkages are supported but must be manually configured, clustering follows the guidelines set by the VNF vendor.
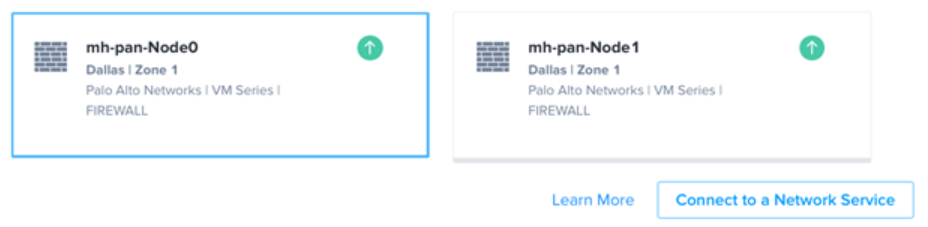
Clustering allows for two VNFs to present as one logical device to the rest of the network. If Node 0 should fail then Node 1 will automatically take over. How fast this failover occurs is dependent on each vendor and the specific configuration. Clustering allows VNFs to take advantage of features like configuration syncing and state-sharing. Note that these features vary by vendor and licensing.
Clustered devices are treated as a single device in the Equinix Portal. Virtual connections that are built to the cluster are connected to both devices but only show as a single connection, because the standby unit inherits the connections of the active unit.

Clustering allows customers to deploy more advanced resilient options for virtual services where high availability is required. It builds upon device redundancy by using vendor features which builds customer confidence that they are deploying in a manner that is familiar to them. This provides options for deploying more complex virtual networks and extends the current use cases for Network Edge.
| Redundant Devices | Clustered Devices | |
|---|---|---|
| Supported Vendors in NE | All | Juniper, Palo Alto Networks, Fortinet |
| Number of Active Devices | 2 | 1 |
| Logical Devices | 2 | 1 |
| Shared Management | No | Yes* |
* As of March 2021, a Palo Alto Networks cluster only allows management access to the active unit. A workaround is being explored to provide access to the standby unit.